
面议

面议

面议

面议

面议
| 有效期至长期有效 | 最后更新2021-06-07 08:45 |

随着机器学习和深度学习等技术的突破,人工智能相关技术被广泛的应用到了各行各业。但是要将学术界、工业界先进的算法模型和实践经验,要快速的应用到自己的业务场景中还是需要做很多工作。
为了能个快速的进行算法相关实验,在实际的工业场景中落地,就需要一个具有高性能,可复用和能灵活迭代的算法平台。
同时,对于一些本身没有算法经验的团队或则个人,也可以使用算法平台,让各种人工智能的算法服务于自己的需求,对于所有人而言,人工智能都将变得唾手可得。
要打造一个满足当前需求的算法平台,需要从计算性能,平台易用性,满足真实业务场景需求等不同的方面进行考量,文本将带你了解如何打造一个面向AI的算法平台。
算法平台简介
算法平台的核心是模型+快速上线,因此算法平台的核心也是这两个模块。但是整个算法平台将有很多模块构成。
可快速调用的模型库,拥有XGBoost、GBDT、text-CNN、bert等主流的机器学习和深度学习模型。
可以根据业务场景灵活拖拽各种复杂的数据预处理和特征工程操作。
底层计算平台,为了满足大数据计算的问题,使用spark提供分布式流处理框架保证在较短的时间内计算出相应的结果。
当实验完成后,可以一键导出当前的预测流进行上线工作,不需要重新编写相关代码进行上线工作,一键完成。
自由的算法组件开放,平台本身只提供通用的常见的一些算法模型和特征工程组件,可以根据自己的业务需求编写相应代码并部署上线。
深度学习中的神经网络结构,可以根据用户的需求自行拖拽,集成了常见的CNN、RNN、LSTM和Dense等不同的网络层。
算法平台计算引擎
算法平台的计算引擎基于用于大数据实时计算的Spark框架。Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache项目,速度之快足见过人之处,Spark以其先进的设计理念,迅速成为社区的热门项目,围绕着Spark推出了Spark SQL、Spark Streaming、MLLib和GraphX等组件,也就是BDAS(伯克利数据分析栈),这些组件逐渐形成大数据处理一站式解决平台。
Spark是在借鉴了MapReduce之上发展而来的,继承了其分布式并行计算的优点并改进了MapReduce明显的缺陷,具体如下:
首先,Spark把中间数据放到内存中,迭代运算效率高。MapReduce中计算结果需要落地,保存到磁盘上,这样势必会影响整体速度,而Spark支持DAG图的分布式并行计算的编程框架,减少了迭代过程中数据的落地,提高了处理效率。
其次,Spark容错性高。Spark引进了弹性分布式数据集RDD (Resilient Distributed Dataset) 的抽象,它是分布在一组节点中的只读对象集合,这些集合是弹性的,如果数据集一部分丢失,则可以根据“血统”(即充许基于数据衍生过程)对它们进行重建。另外在RDD计算时可以通过CheckPoint来实现容错,而CheckPoint有两种方式:CheckPoint Data,和Logging The Updates,用户可以控制采用哪种方式来实现容错。
,Spark更加通用。不像Hadoop只提供了Map和Reduce两种操作,Spark提供的数据集操作类型有很多种,大致分为:Transformations和Actions两大类。Transformations包括Map、Filter、FlatMap、Sample、GroupByKey、ReduceByKey、Union、Join、Cogroup、MapValues、Sort和PartionBy等多种操作类型,同时还提供Count, Actions包括Collect、Reduce、Lookup和Save等操作。另外各个处理节点之间的通信模型不再像Hadoop只有Shuffle一种模式,用户可以命名、物化,控制中间结果的存储、分区等。
算法平台模型库
算法平台模型库主要包括三部分:
是由平台提供的通用算法库
可以由用户自主拖拽网络结构构建的算法库
由用户自行编写代码上传发布上线的算法库
和市面上的大多数机器学习平台类似,我们平台也提供了一些常用的算法,和主流的数据预处理和特征工程等操作,对于很多AI应用人员或则一些非AI类企业,可以使用算法平台自动进行模型训练、数据分析和特征工程。对于很多AI从业者和企业,可以快速获得AI能力,赋能于自己的业务场景,不需要过多的关注于算法本身的实现机制,就可以通过拖拽的方式,可视化的实现各种算法在自己业务场景中的应用。
随着深度学习的快速发展,其在图像,自然语言处理以及语音等相关领域都表现出了非常良好的性能。而深度学习的实现往往依赖于不同的神经网络层,算法平台将提供各种基础网络层,如果一些拥有算法能力的团队和个人,可以根据自己实际的业务场景,拖拽网络层,得到当前场景下的算法。
算法多种多样,加上各种数据预处理和特征工程相关的操作,有成千上万种,不可能都由平台提供,还有一些涉及到具体的业务场景的操作也不可能提前集成在算法平台上。这个时候就可以提供用户自行开发组件,根据一定的代码规范,可以使用python开发自己的组件并进行上线,可以进行自己算法的研究,也可以设计更满足自己的业务场景的相关数据处理和特征工程组件。
算法模型一键上线
当在算法平台完成了模型的调试或则开发之后,需要部署上线。因为线上环境和本地环境不同,在传统的算法平台,如果需要上线相应的模型,数据预处理等操作需要在线上环境进行重新实现,这对于开发人员即是工作量很大的事情也同时也可能会产生一些不必要的bug。因为当前算法平台支持一件导出预测pipeline到线上环境。在算法平台进行训练的时候,算法平台后台就会生成相应的训练pipeline和预测pipeline,这个对于用户本身是没有感知的,当完成训练并得到相应的可以上线的模型后,可以使用一键上线功能,就可以省去本身需要在线上环境中再重新实现的相关功能需求。
写在
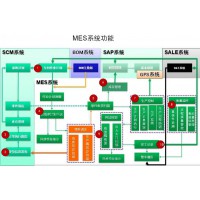
为了降低算法在实际应用场景中的使用门槛,完成模型的快速训练上线。实际中的算法平台会打通数据平台,和打标平台和线上环境进行一整个流程的工作,工作流程图如下图所示:
为了降低算法在实际应用场景中的使用门槛,完成模型的快速训练上线。实际中的算法平台会打通数据平台,和打标平台和线上环境进行一整个流程的工作,工作流程图如下图所示:(重要的话说2遍)
该图出自作者,UI请假烫头
打造数据到算法模型的全流程大闭环,可以真正的将Al能力体现在各种业务场景中,而算法平台正是其中重要的一环,也是打通全链路的关键节点,所以一个好的算法平台可以起到很好地保障作用。
例如这样:
代发 b2bhttp://www.b2bxc.com/


¥1.00/件

¥100.00/套
面议
面议

面议
¥1500.00/台
¥5500.00/平方米
面议
¥26.00/公斤
¥26.00/公斤
 客服热线:
客服热线:










&tel=13868850106&work=13868850106&email=&org=杭州实在智能科技有限公司&adr=浙江省杭州市余杭街道人工智能小镇6号楼6楼&url=https://www.oemao.com/com/shizai010/)